Surgical tools detection

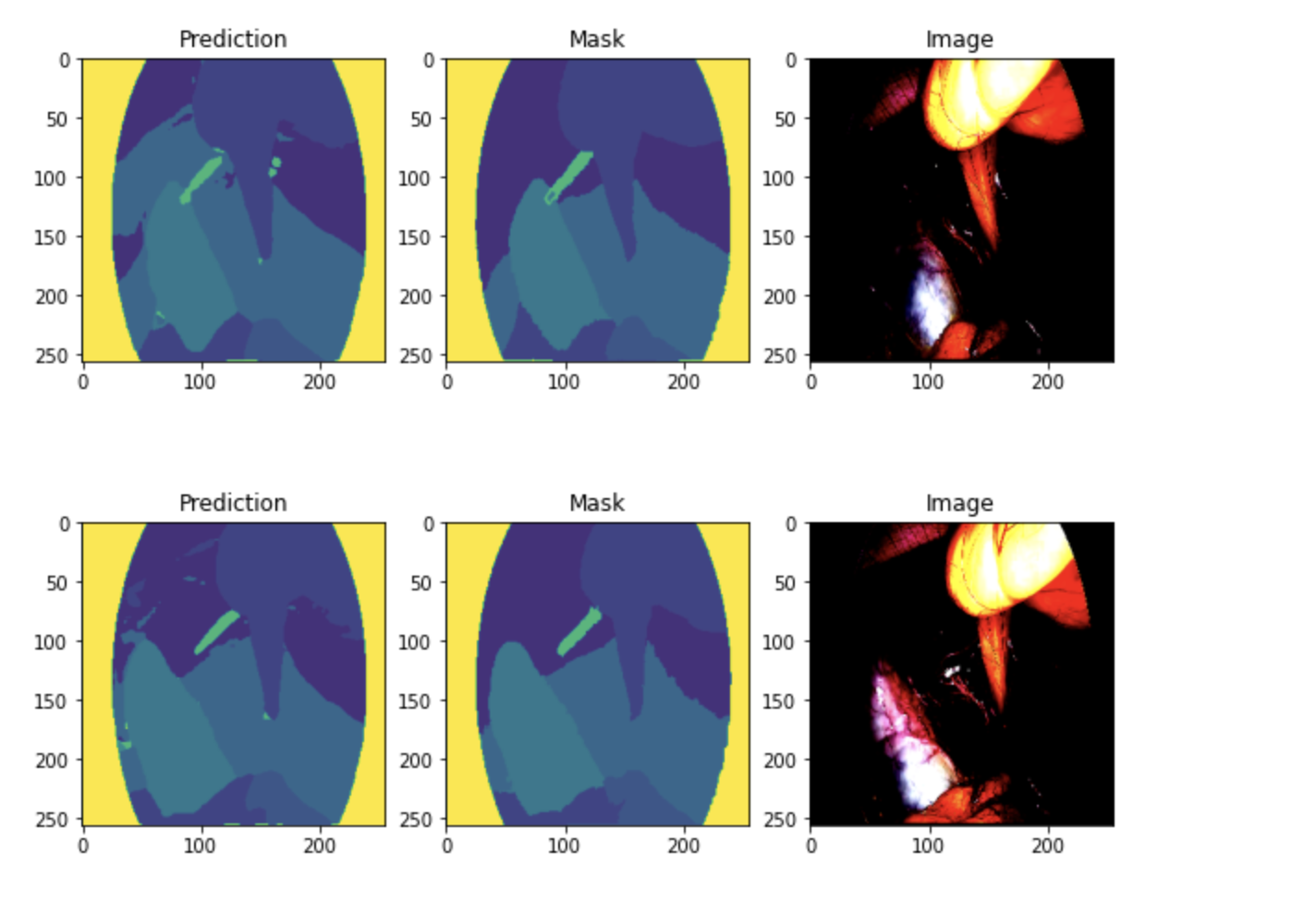
This week I was training the Surgical Tools Detection model. The dataset was taken from here . To train the model and prepare it for inference I was using Roboflow. Roboflow is a robust web-platform for collecting datasets, training models and running them into production. Training I have split the data on 69/21/10 for train, val and test sets. Graphs with training metrics is shown below Train / val metrics To be more precise, on test set the model has 93.8% precision with 90% recall and 96.4% mAP. It is considered as a high performance and means that the model can be used in production. Inference Roboflow itself provides multiple ways for inference. I could use web-API method (requests are sent to the server and the model sends back predictions), but to make it more flexible, I prefer python-package method. It can be easily imported to the main project of LibreHealth and run.