GSoC week 2: developing a model for semantic segmentation

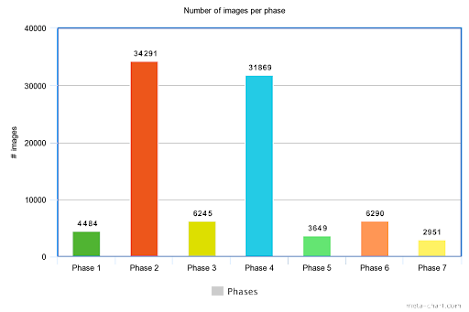
This week I was developing models for medical images segmentation in VR. Data I was working with two datasets: binary semantic segmentation dataset and multi class semantic segmentation dataset. The binary segmentation was done using Polyp Segmentation in Colonoscopy data. This dataset contains 300 images with binary masks. The multi class segmentation was done using Cholec8K dataset. This dataset contains 8080 laparoscopic cholecystectomy image frames from 17 videos from Cholec80 dataset. Model and training For both segmentation tasks I was using the DeepLabV3Plus model with ResNet50 encoder, pretrained on imaginet data set. For polyp segmentation I was using 80% of data for training and 20% for validation-testing. In case of Cholec8k I decided to make the train-test-split based on videos. 12 videos were taken for training and 5 for testing. For training I was using the open source Catalyst framework and SMP . It reduced the...