Summing up my GSoC experience
Introduction
Once again, I am Daniil Orel from Kazakhstan (Nur-Sultan / Astana city). This summer I was working with LibreHealth organisation for an amazing GSoC project.
Few words about my host organisation
LibreHealth is a collaborative community, which supports free open source software projects in HealthTech. This organisation has multiple projects, but I was working towards the radiology project.
My project
Several medical procedures in surgery or interventional radiology are recorded as videos used for review, training, and quality monitoring. These videos have at least three interesting artifacts - anatomical structures such as organs, tumors, tissues, etc.; medical equipment, and medical information overlaid that describes the patient. It will be immensely helpful for review and search purposes if these can be identified and automatically labeled in the videos.
My task was to develop ML models which can process videos and that are suitable for VR environment. As a result, I have developed ML models for classification, segmentation and detection of surgical tools in VR. Additionally I have developed an ML model for polyps and organs segmentation.
Work done
There are 4 major paths of my work.
Classification
Classification task was simple: given a crop with a surgical tool, I had to classify it.
 |
| Example of crops |
 |
| Model AUC |
- Running classification model as a script from file
- Running classification model from other packages
The first option can be used if there are is a folder with surgical tools crops and it is needed to classify them. It can be run using the following command from the classification folder:
python inference_scripy.py --img-dir="DIRECTORY WITH IMAGES" --save-to="OUTPUT DIRECTORY" --onnx-model-path="ONNX FILE" --seg-type="SEGMENTATION TYPE"
The second option is suitable for cases when a model should be called from another functions and/or classes. Such implementation makes the system more flexible.
More details are in this commit.
Segmentation
Segmentation task was split on two parts:
- Binary polyp segmentation
- Multi class segmentation (organs and surgical tools)
For binary segmentation the model was able to segment polyps with high accuracy:
 |
| Polyp segmentation examples |
In case of multi class segmentation, results are great as well:
 |
| Multi class segmentation examples |
- One for processing video (applying segmentation to frames) in an online mode
- Rewriting a video, after processing it (applying segmentation to all frames and writing them as another video)
The video processor class is defined here. Examples of how to use it for segmentation can be found in "examples" folder. Example from here generates the frames like the one below:
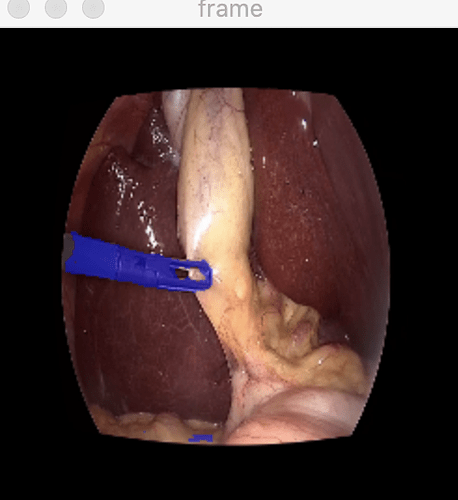 |
| Example of video segmentation |
Detection
Detection task was performed for surgical tools. The model was trained using roboflow framework. Results of training are here:
 |
| Detection model training |
Inference for this model is similar to the one for segmentation. The only difference is that this model requires Internet-connection, since my model is hosted on roboflow service.
System as whole
 |
| A small system diagram |
To explain how the whole system works, I can use a simple diagram. The figure above shows that there are 4 possible ML models. Each of them can be used as a backbone in the annotator pipeline.
It means that any model can be used as a processing tool within the VideoProcessor class, while this class can be used inside Video Writer, to write the processed videos.
Examples of how to use it can be found here. More precisely, processing pipeline for segmentation is here , while the pipeline for detection is here. Examples for writing video files using detection and segmentation models are also available.
Merged pull requests and commits
My work and merged pull requests is here:
Conclusion
To sum up, I have successfully finished the GSoC. All required ML models were developed. Additionally I have developed the inference pipelines for 3 different use cases: use as a script, use as a function and video processing.

Comments
Post a Comment